AFL使用指南
0x00 前言
二进制分析方面主要利用技术包括:动态分析(Dynamic Analysis)、静态分析(Static Analysis)、符号化执行(Symbolic Execution)、Constraint Solving、资讯流追踪技术(Data Flow Tracking)以及自动化测试(Fuzz Testing)
AFL原理介绍参考:
《AFL漏洞挖掘技术漫谈(一):用AFL开始你的第一次Fuzzing》
本指南使用的环境是 kali linux 2019.1
0x01 AFL的基本使用
1. 使用afl-gcc
1.1 使用AFL插桩程序
目标程序
1 |
|
使用afl-gcc进行插桩编译
1 | afl-gcc -g -o ./zerotest/vuln ./zerotest/vuln.c |
PS:
如果目标程序中有Makefile,那么分两种情况:
- 程序是用autoconf构建,那么此时只需要执行如下即可
1 | ./configure CC="afl-gcc" CXX="afl-g++" |
此外,还可以执行如下语句设置LD_LIBRARY_PATH让程序加载经过AFL插桩的.so文件,进行静态构建而不是动态链接
1 | ./configure --disable-shared CC="afl-gcc" CXX="afl-g++" |
- 程序不是用autoconf构建,那么直接修改Makefile文件中的编译器为
afl-gcc/g++。
为了后期更好的分析crash,在此处可以开启Address Sanitizer(ASAN)这个内存检测工具,此工具可以更好的检测出缓存区溢出、UAF 等内存漏洞,开启方法如下:
1 | AFL_USE_ASAN=1 ./configure CC=afl-gcc CXX=afl-g++ LD=afl-gcc--disable-shared |
不使用 AFL 编译插桩时,可使用以下方式开启 Address Sanitizer。
1 | ./configure CC=gcc CXX=g++ CFLAGS="-g -fsanitize=address" |
1.2 开始fuzz
fuzz的语法一般情况是两种:
- 直接从stdin读取输入的目标程序
1 | $ ./afl-fuzz -i testcase_dir -o findings_dir /path/to/program […params…] |
- 从文件读取输入的目标程序,@@就是占位符,表示输入替换的位置
1 | $ ./afl-fuzz -i testcase_dir -o findings_dir /path/to/program @@ |
此处我采用第一种方式
1 | afl-fuzz -m 300 -i ./zerotest/fuzz_in -o ./zerotest/fuzz_out ./zerotest/vuln -f |
PS: 常见参数的含义如下
- -f参数表示:testcase的内容会作为afl_test的stdin
- -m参数表示分配的内存空间
- -i 指定测试样本的路径
- -o 指定输出结果的路径
- /dev/null 使错误信息不输出到屏幕
- -t:设置程序运行超时值,单位为 ms
- -M:运行主(Master) Fuzzer
- -S:运行从属(Slave) Fuzzer
1.3 fuzz的结果
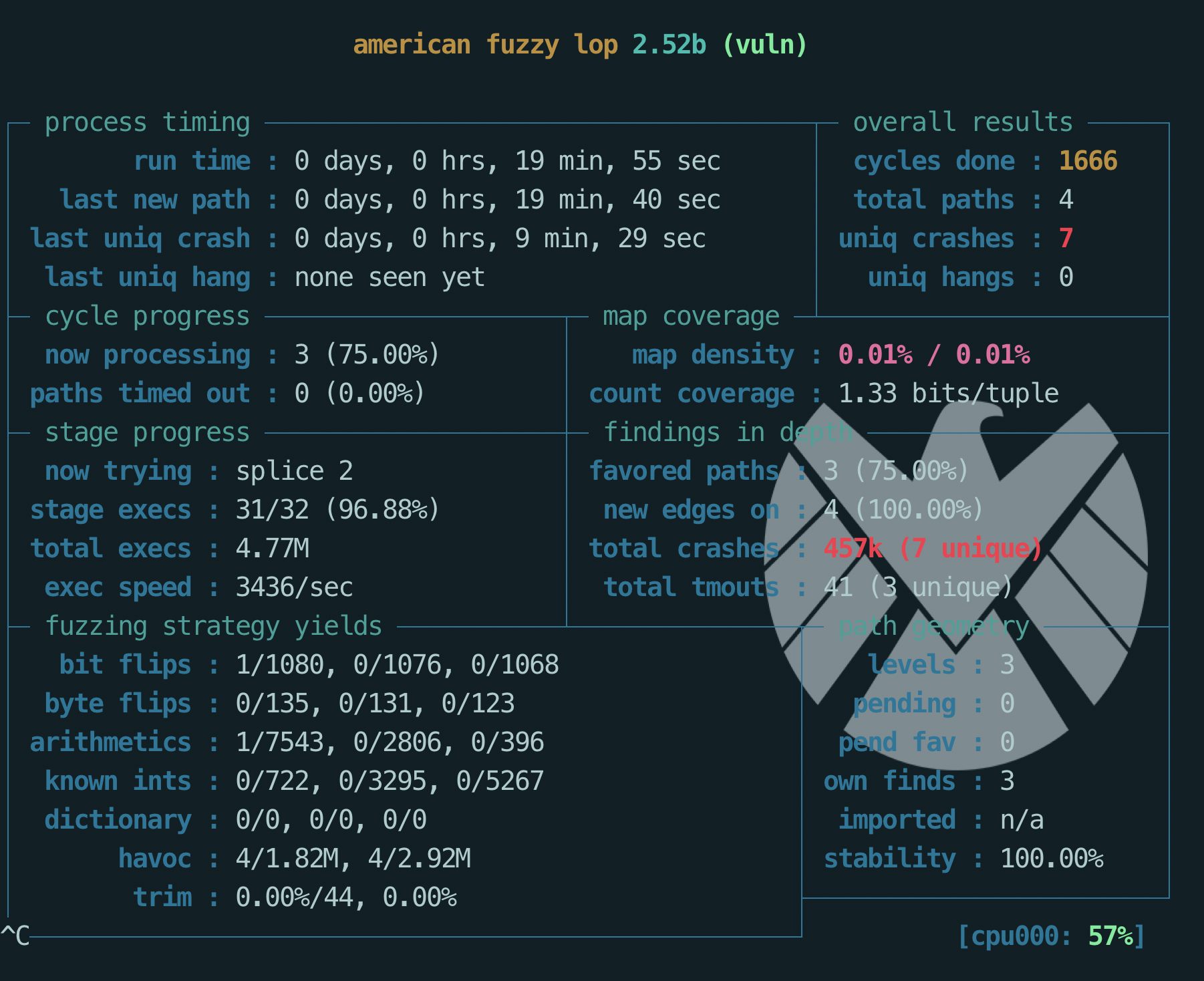
从界面上主要注意以下几点:
- last new path 如果报错那么要及时修正命令行参数,不然继续fuzz也是徒劳(因为路径是不会改变的);
- cycles done 如果变绿就说明后面及时继续fuzz,出现crash的几率也很低了,可以选择在这个时候停止
- uniq crashes 代表的是crash的数量
1.4 crash分析
PS: xxd命令的作用就是将一个文件以十六进制的形式显示出来
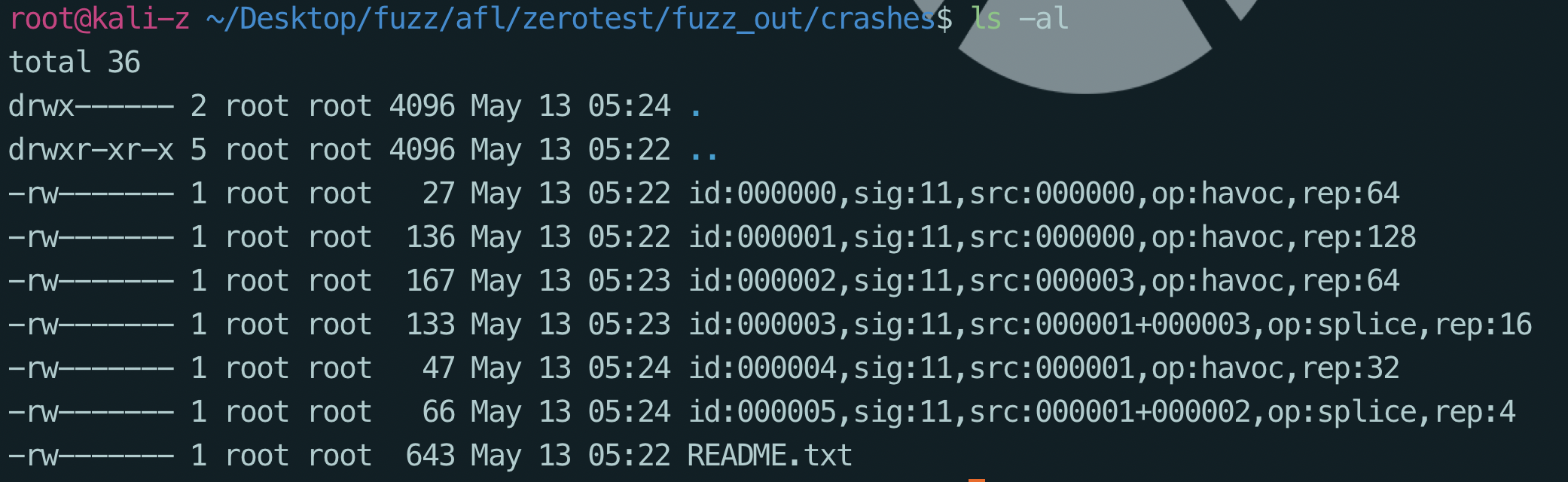
可以看到已经得到的几个crash文件,那么分析的话只需要将其作为之前vuln文件的输入,使用gdb调试分析就可以得到详细结果了,但是在这之前可以使用xxd看一下其中数据的内容做一个初步的判断。
分别看一下这几个crash的信息
- 可以看到应该是满足了开头是F且字符串长度为6的异常退出情况

- 看这个数据情况可能是栈溢出
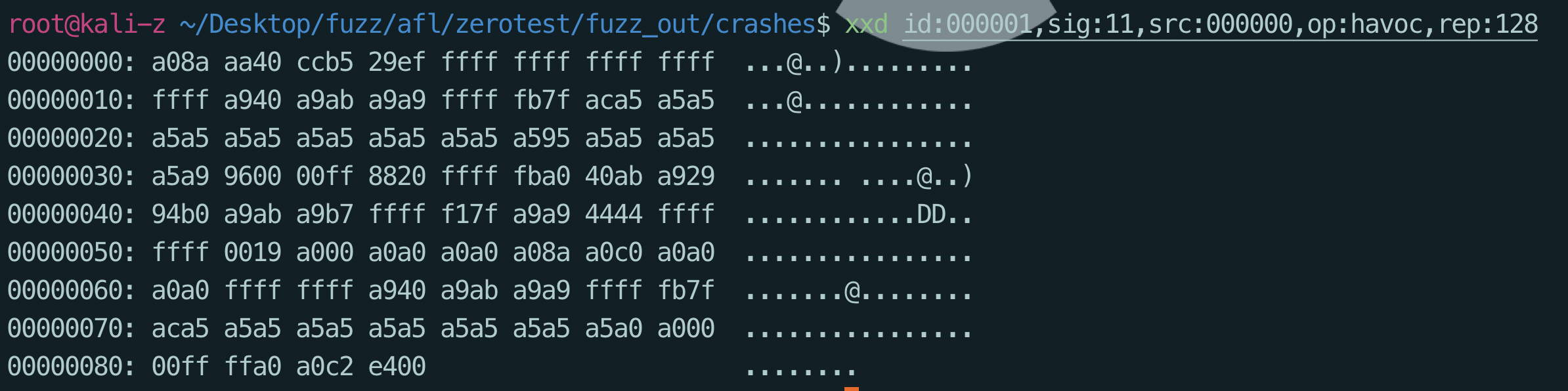
- 栈溢出
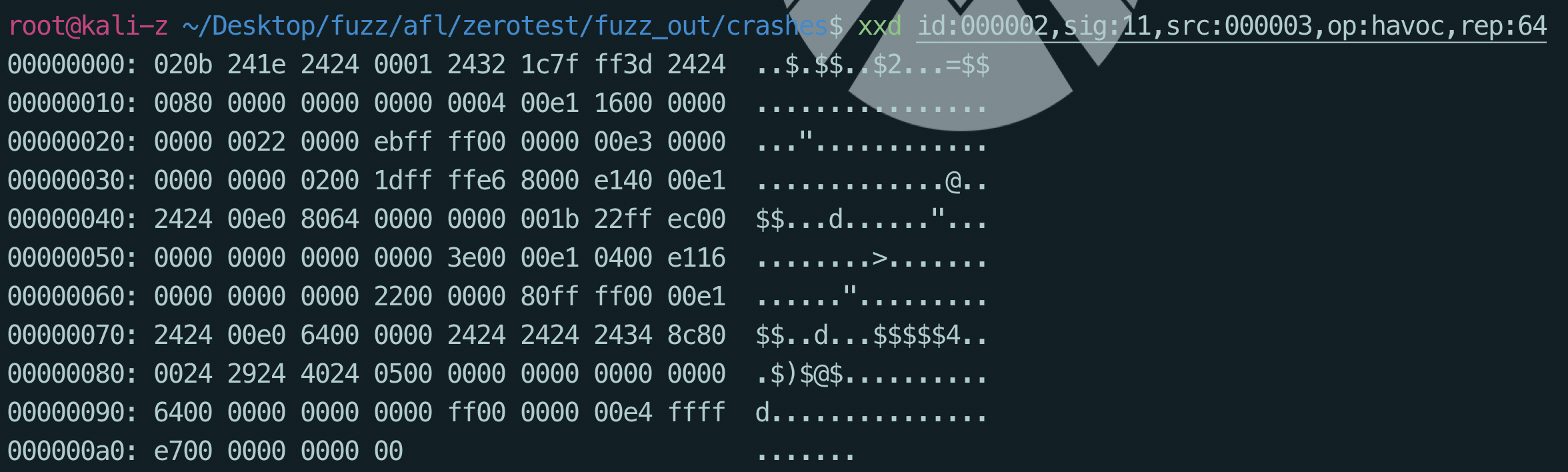
- 符合首字符为A且栈溢出
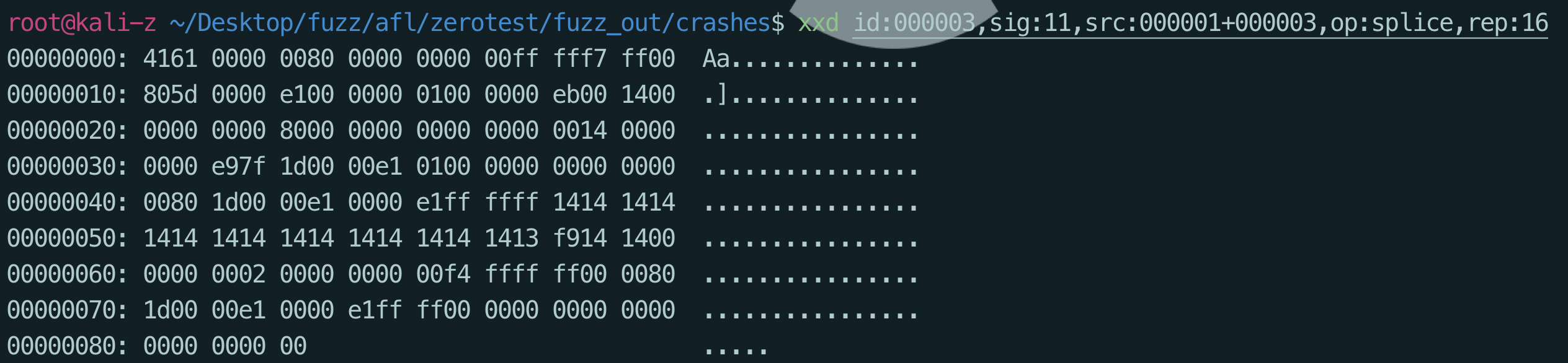
- 格式化字符串?可能

- 符合首字符为A且字符串长度为66的异常退出情况

主要参考:
《初探Fuzz-AFL》
1.5 语料库蒸馏(Corpus Distillation)
一般来说在进行fuzz之前构建一份有效的语料库是十分有必要的,这将作为程序开始时的种子。
语料库的信息来源主要如下:
- 使用项目自身提供的测试用例
- 目标程序bug提交页面
- 使用格式转换器,用从现有的文件格式生成一些不容易找到的文件格式:
- afl源码的testcases目录下提供了一些测试用例
- 其他开源的语料库
收集完后可以使用afl提供的工具来对语料库进行进一步的处理:
- afl-cmin: 移除执行相同代码的输入文件
afl-cmin的核心思想是: 尝试找到与语料库全集具有相同覆盖范围的最小子集。
它一般的两种执行模式是:
1 | afl-cmin -i input_dir -o output_dir -- /path/to/tested/program [params] |
1 | afl-cmin -i input_dir -o output_dir -- /path/to/tested/program [params] @@ |
- afl-tmin: 减小单个输入文件的大小
它有两种工作模式: instrumented mode和crash mode。默认的工作方式是instrumented mode
1 | # instrumented mode |
1 | # crash mode 将会剔除导致crash的文件 |
由于只能针对单个目标进行使用,因此使用如下shell脚本进行批量处理
1 | for i in *; do afl-tmin -i $i -o tmin-$i -- ~/path/to/tested/program [params] @@; done; |
或者修改如下的Python脚本进行预处理
1 | import os |
预处理脚本来自:《使用 AFL 进行模糊测试》
2. LLVM Mode模式
2.1 启用llvm
LLVM Mode模式编译程序可以获得更快的Fuzzing速度,因此针对大型项目可以考虑启用。
下载必要的安装包
1 | wget http://releases.llvm.org/8.0.0/llvm-8.0.0.src.tar.xz |
解压缩
1 | xz -d ./* |
源码合并
1 | mv cfe-8.0.0.src clang |
编译安装
1 | mkdir build-8.0 |
上面的编译安装对硬件配置和硬盘的空间要求比较高,所以你可以直接使用源进行安装,比如:
1 | apt install llvm clang |
编译安装afl的llvm模块
(我的使用的是kali linux 2019.1进行编译的,clang版本过高会失败,使用clang++也会失败,所以最终发现下面方法可行)
1 | cd afl/llvm_mode |
因为clang没有办法使用update-alternatives,因此我直接修改软连接
1 | ln -s /usr/bin/clang-6.0 /usr/bin/clang |
之后就可以正常使用afl-clang-fast了
其实以上均太费劲,还有更简单的方法,kali linux的源中包含了afl,所以可以直接apt进行安装,装好之后afl-clang-fast也就有了
1 | apt install afl |
2.2 使用LLVM Mode模式进行fuzz
编译插桩
1 | root@kali-z ~/Desktop/fuzz/afl$ ./afl-clang-fast -g -o ./zerotest/vuln-fast ./zerotest/vuln.c |
之后重复上面的方式进行fuzz即可,接下来展示一个使用此模式fuzz php内核代码的例子。
1. 下载目标代码
1 | wget https://github.com/php/php-src/archive/php-7.2.11.tar.gz && tar xf php-7.2.11.tar.gz |
2. 进行编译插桩
1 | cd php-src-php-7.2.11 |
PS: 如果报错缺失libconv,则在Makefile中的EXTRA_LIBS =添加-liconv
3. 进行源代码的修改
未修改之前 sapi/cli/php_cli.c
修改之后 sapi/cli/php_cli.c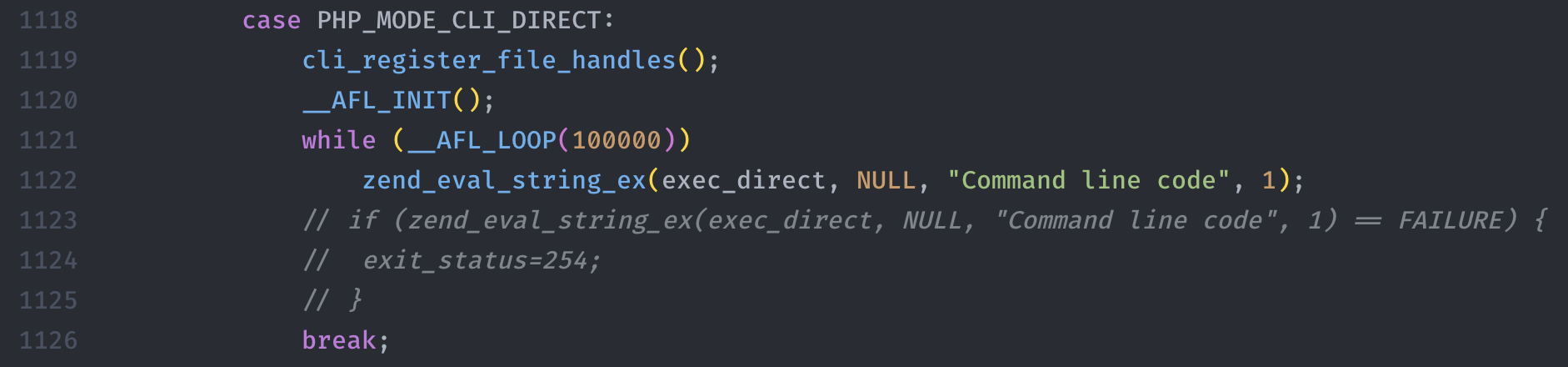
修改完之后执行如下进行rebuild
1 | AFL_USE_ASAN=1 make |
PS: 之所以进行这样的修改,是因为我们使用php -r来eval php string,因此定位到sapi/cli/php_cli.c进行代码的修改离开提升后期fuzz的效率。
4. 构造一个输入点
我们想在fuzz的时候从stdin进行数据的输入,因此构造如下输入点
1 | unserialize(file_get_contents(“php://stdin”)); |
5. 根据上述的构造点构造输入数据
此处账户要考虑构造不同类类型的输入数据,构造如下
1 | mkdir serialized_data && cd serialized_data |
6. 开始fuzz
为了从地址清理(ASAN)中获得有用的结果,有必要设置一个环境变量,以便PHP禁用其自定义内存分配器,从而使内存安全问题对ASAN可见。
1 | USE_ZEND_ALLOC=0 screen -S zeroyu |
使用screen可以随时进入查看fuzz的结果
1 | screen -r zeroyu |
使用如下命令开始fuzz
1 | cd.. |
7. 分析crash
用是使用如下bash脚本来寻找可能是bug的crash,因为有些是良性的crash,是由于ASAN无法分配足够的内存。这是因为ASAN需要额外的内存来跟踪所有分配,而精心编制的序列化对象可能会触发大内存分配。
1 | for FILE in $(ls id*); do cat $FILE | ../../sapi/cli/php -r "unserialize(file_get_contents('php://stdin'));" 2>&1 | grep -E "SUMMARY|ERROR" | grep -v "LargeMmap" && echo $FILE; done |
参考: 《Fuzzing PHP for Fun and Profit》
3. 黑盒测试
参考:《AFL漏洞挖掘技术漫谈(一):用AFL开始你的第一次Fuzzing》
4. 并行测试
4.1 单系统并行
查看系统核心数
1 | cat /proc/cpuinfo| grep "cpu cores"| uniq |
afl-fuzz并行Fuzzing,一般的做法是通过-M参数指定一个主Fuzzer(Master Fuzzer)、通过-S参数指定多个从Fuzzer(Slave Fuzzer)。
1 | $ screen afl-fuzz -i testcases/ -o sync_dir/ -M fuzzer1 -- ./program |
PS: -o指定的是一个同步目录,并行测试中,所有的Fuzzer将相互协作,在找到新的代码路径时,相互传递新的测试用例。所以不用担心重复的问题
两个辅助工具:
afl-whatsup工具可以查看每个fuzzer的运行状态和总体运行概况,加上-s选项只显示概况,其中的数据都是所有fuzzer的总和。afl-gotcpu工具可以查看每个核心使用状态。
4.2 多系统并行
压缩每个fuzzer实例目录中queue下的文件,通过如下SSH脚本同步分发到其他机器上解压。
1 |
|
0x02 Fuzz结果分析和代码覆盖率
1. 工作状态
afl-fuzz永远不会停止,所以何时停止测试很多时候就是依靠afl-fuzz提供的状态来决定的。具体的几种方式如下所示:
- 状态窗口的
cycles done变为绿色; afl-whatsup查看afl-fuzz状态;afl-stat得到类似于afl-whatsup的输出结果;- 定制
afl-whatsup->在所有代码外面加个循环就好; - 用
afl-plot绘制各种状态指标的直观变化趋势; pythia估算发现新crash和path概率。
2. fuzz结束判断
- 状态窗口中”cycles done”字段颜色变为绿色该字段的颜色可以作为何时停止测试的参考;
- 距上一次发现新路径(或者崩溃)已经过去很长时间了,至于具体多少时间还是需要自己把握;
- 目标程序的代码几乎被测试用例完全覆盖,这种情况好像很少见;
- pythia提供的各种数据中,path covera达到99或者correctness的值达到1e-08(含义: 从上次发现path/uniq crash到下一次发现之间大约需要1亿次执行)
3. 输出结果说明
queue:存放所有具有独特执行路径的测试用例。
crashes:导致目标接收致命signal而崩溃的独特测试用例。
crashes/README.txt:保存了目标执行这些crash文件的命令行参数。
hangs:导致目标超时的独特测试用例。
fuzzer_stats:afl-fuzz的运行状态。
plot_data:用于afl-plot绘图。
4. 对crash结果的简单分析和分类
- crash exploration mode
afl-fuzz的一种运行模式,也称为peruvian rabbit mode,用于确定bug的可利用性,其输入的是crash的信息,之后使用-C启用这种模式,afl会自动探索并创造与之相关的crash来帮助你进行分析,比如判断能够控制某块内存地址的长度。
1 | afl-fuzz -m none -C -i ./fuzz_out/crashes -o ./peruvian-were-rabbit_out -- ./vuln -f |
- triage_crashes.sh
AFL源码的experimental目录中有一个名为triage_crashes.sh的脚本,可以帮助我们触发收集到的crashes。
直接使用脚本跟参数的话,我们可以看到相关crash情况的寄存器等信息,但是如果只是大致分类的话,可以使用如下命令
1 | /root/Desktop/fuzz/afl/experimental/crash_triage/triage_crashes.sh ./fuzz_out ./vuln 2>&1 | grep SIGNAL |
效果如下,11代表了SIGSEGV信号,有可能是因为缓冲区溢出导致进程引用了无效的内存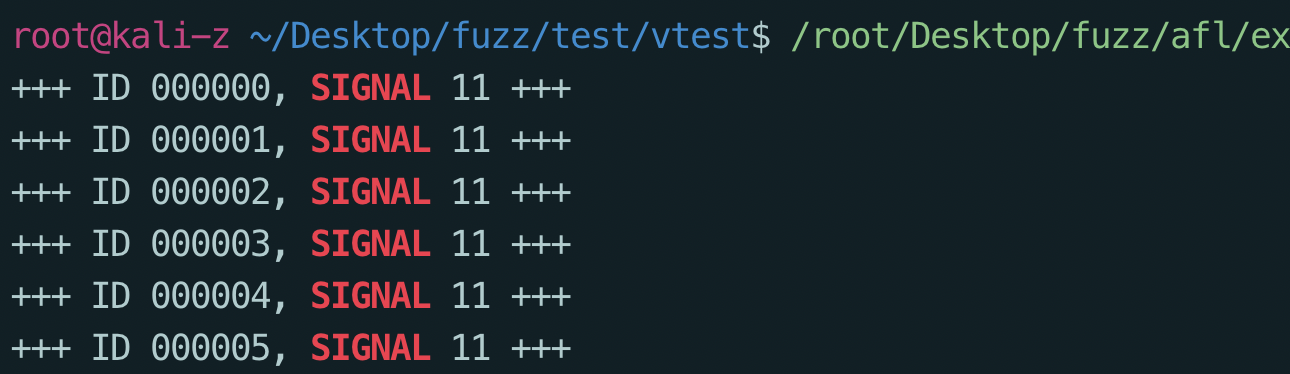
- crashwalk
优点:可以显示更为详细的信息
项目地址: https://github.com/bnagy/crashwalk
1 | # 手动模式 |
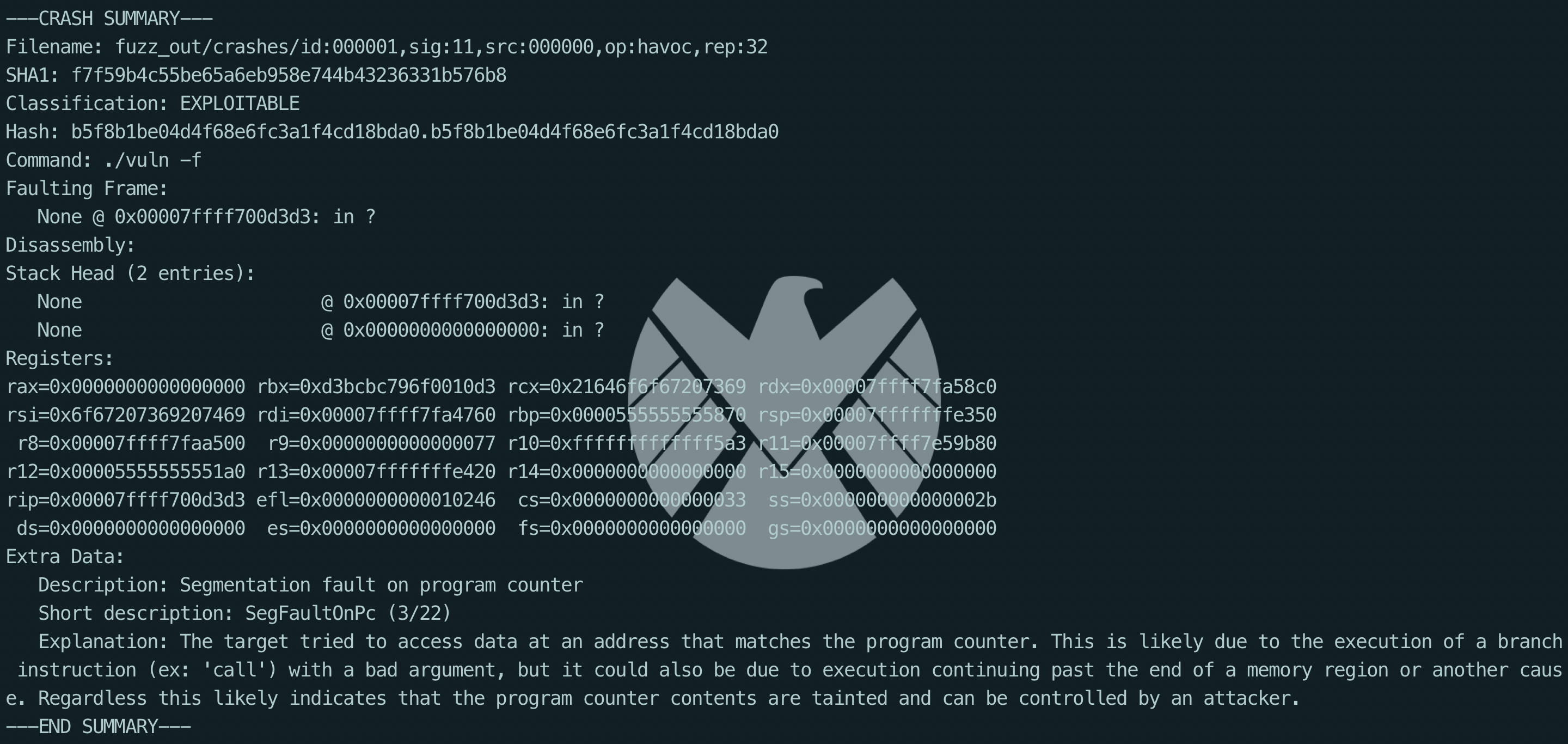
- afl-collect
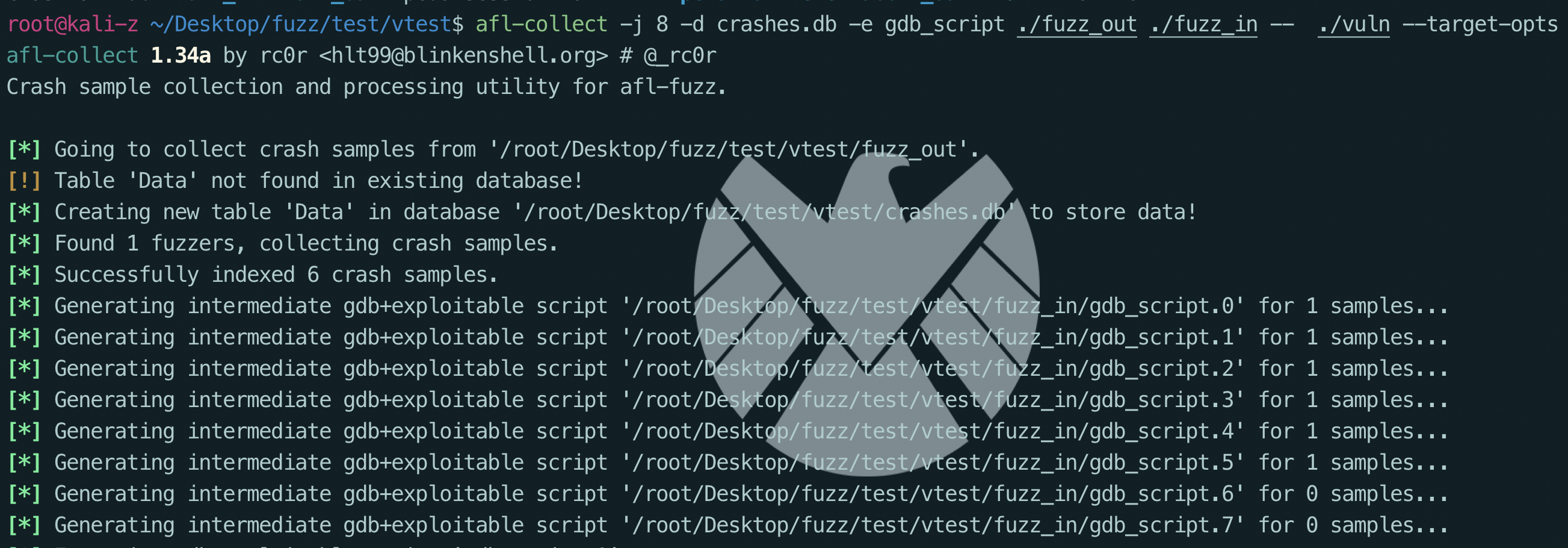
项目地址: https://github.com/rc0r/afl-utils
afl-collect基于exploitable来检查crashes的可利用性。它可以自动删除无效的crash样本、删除重复样本以及自动化样本分类。
1 | afl-collect -j 8 -d crashes.db -e gdb_script ./fuzz_out ./fuzz_in -- ./vuln --target-opts |
效果如下
5. 代码覆盖率
原理部分参考:
《AFL漏洞挖掘技术漫谈(二):Fuzz结果分析和代码覆盖率》
afl-cov的使用说明如下:
首先使用gcov重新编译源码
1 | gcc -fprofile-arcs -ftest-coverage vuln.c -o vuln_cov |
如果遇到需要make进行编译的文件,执行如下:
1 | $ make clean |
之后使用afl-cov来计算覆盖率
1 | afl-cov -d ./fuzz_out --live --enable-branch-coverage -c . -e "cat AFL_FILE | ./vuln_cov AFL_FILE" |
同时进行对插桩过的vuln的fuzz
1 | afl-fuzz -i ./fuzz_in -o ./fuzz_out ./vuln -f |
最终效果如下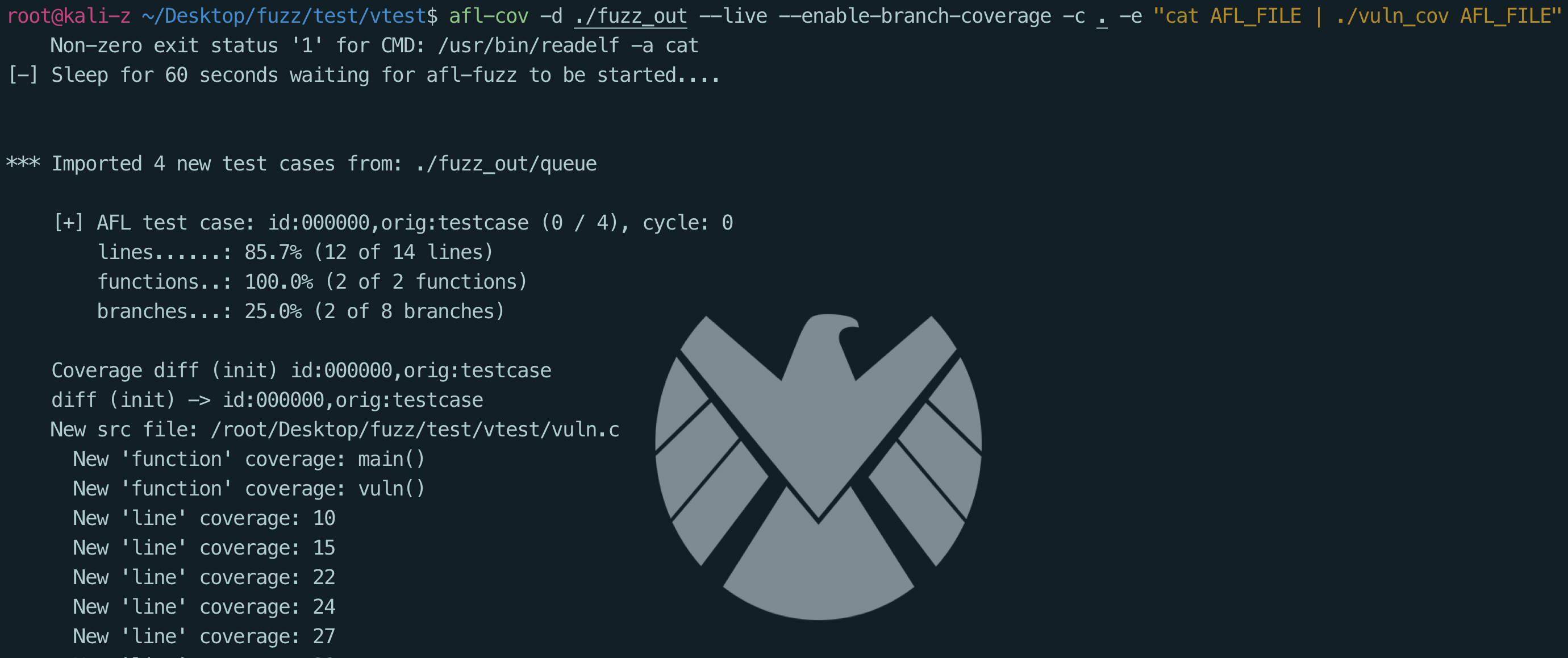
生成的报告会保存在/path/to/afl-fuzz-output/cov/web/lcov-web-final路径下。