Razzer-Finding Kernel Race Bugs through Fuzzing
出处:S&P 2019
作者:Dae R. Jeong, Kyungtae Kim, Basavesh Shivakumar, Byoungyoung Lee, Insik Shin
单位:Computer Science, KAIST, Computer Science, Purdue University, Electrical and Computer Engineering, Seoul National University
资料:Paper
摘要
内核中的数据竞争是一类严重的bug,会影响相关系统的可靠性和安全性。利用内核中的竞争,简单的可以是内核变得没有响应, 严重的则会触发权限提升攻击以获取root权限。
本文将主要基于RAZZER,一种在内核中查找竞争漏洞的工具,来介绍对内核数据竞争漏洞的模糊测试。一般的模糊测试是通过输入畸形数据来触发目标程序的崩溃进而再通过手动分析确定是否存在安全问题的,但是这种方式不仅很难对竞争漏洞进行针对性测试,而且很难发现由于竞争漏洞而导致的潜在安全问题。与传统方案的不同,RAZZER的核心思想是引导Fuzzing工具去执行可能存在数据竞争漏洞的代码。具体来说就是采用静态分析和确定性线程交错技术。静态分析技术来对潜在的内核数据竞争点进行定位,从而引导Fuzz器更有效地对内核中的数据竞争点进行Fuzz。确定性线程交错技术则是用来控制线程调度,以提供精确的并行执行信息,降低不确定性,从而保证内核竞争的稳定触发。但是此项工作并没有解决同步机制对多线程模糊测试的影响。
I 介绍
数据竞争对底层系统的可靠性和安全性会造成影响,具体来说主要是以下三个方面:
- 如果数据竞争引入了循环锁定行为,则由于导致的死锁,造成内核无响应。
- 如果出现在内核中的安全断言,内核将自行重启,从而导致拒绝服务。
- 数据竞争还可能会导致严重的安全攻击,比如触发缓冲区溢出或者UAF等类型的漏洞进而导致权限提升攻击。例如CVE-2016-8655 [1],CVE-2017-2636 [2]和CVE-2017-17712 [3]。
因为数据竞争源于内核的非确定性行为,所以研究数据竞争不仅需要精确的控制流和数据流信息,还需要精确的并发执行信息,这些信息受到底层系统的许多其他外部因素(例如调度,同步原语等)的严重影响。
本文介绍的RAZZER首先进行使用LLVM传递实现了静态分析以获得潜在数据竞争点,之后针对这些竞争点执行两次动态模糊测试。第一次是单线程模糊测试,其重点是找到执行潜在竞争点的单线程输入程序(不考虑程序是否确实触发了竞争)。第二次是多线程模糊测试,使用自建的多线程程序,进一步利用修改QEMU和KVM开发的管理程序来促使其在潜在数据竞争点的执行。因此,RAZZER能够避免外部因素的影响使竞争行为稳定触发。
RAZZER的主要特点如下:
- 面向竞争的Fuzzer:这是一种新的模糊测试机制,专门用于检测内核中的竞争。 它利用静态和动态分析技术将其模糊测试集中在潜在的竞争点上。
- 强大的实现:基于各种行业优势框架实施了RAZZER,主要是KVM / QEMU和LLVM。 它不需要手动修改要分析的目标内核,从而可以轻松支持最新的Linux内核而无需任何人工干预。
- 实际效果:RAZZER发现了30个竞争漏洞,其中16个已经被确认,并由相应的内核开发人员进行相应的修复。
II 问题定义&设计需求
A.问题定义
当目标程序中的两个存储器访问指令满足以下三个条件时,发生数据竞争:
(i)访问的内存地址相同。
(ii)至少其中一条指令是对内存的写。
(iii)两条指令可以并发执行。
数据竞争并不都会触发漏洞,有些是开发人员预期的(或有意的)数据竞争,容忍计算结果的潜在偏差。只有那些会触发非预期行为的数据竞争才会触发漏洞。此处引入如下四个术语来进行标识:
RacePaircand 可能导致竞争的两个内存访问指令
RacePairtrue 两个被确认引起竞争的指令
RacePairbenign 预期的数据竞争
RacePairharm 会触发漏洞的非预期数据竞争
此处以竞争漏洞CVE-2017-2636作为示例来阐述数据竞争是如何发生的并且发生之后将会触发什么危害。此漏洞的详情如图1所示,造成漏洞的原因是本应是一个特定顺序的系统调用的特定列表,但却因为一个对抗的多线程用户程序引发了数据竞争,最终在内核处理此类系统调用,比如ioctl和write时导致了double-free问题。
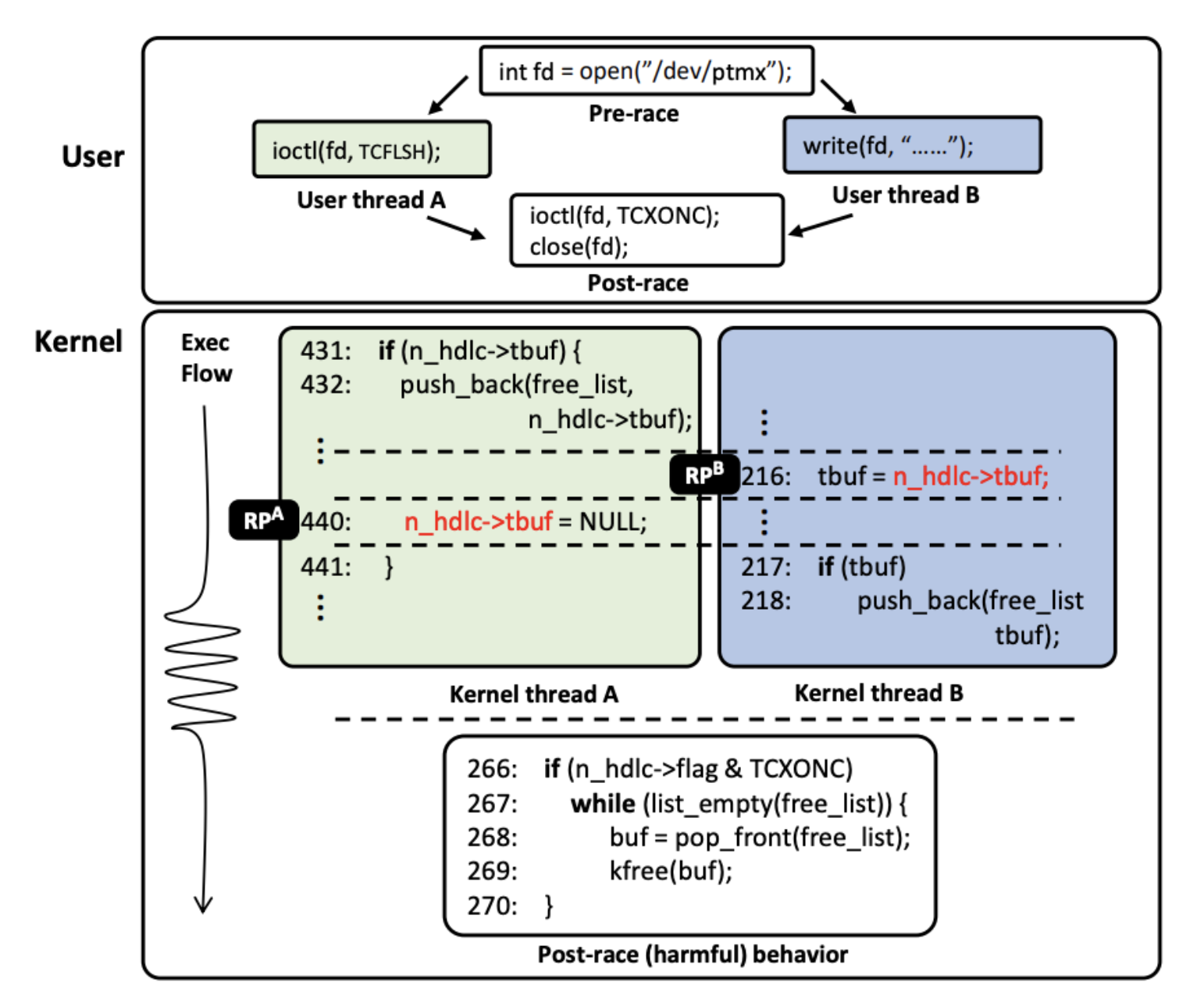
图1:关于CVE-2017-2636的简化竞争示例。 当用户程序同时执行两个系统调用时,n_hdlc-> tbuf上的数据竞争可能会发生,但具体要取决于执行顺序,这会情况会导致double-free问题,从而允许攻击者启动权限提升攻击。
B.设计需求
设计要求 为了避免检测竞争过程中出现任何误报,确定出以下两个理想的设计要求:
R1:找到执行RacePaircand的输入程序。 更确切地说,分析应该发现一个多线程用户程序,程序中的每个线程执行RacePaircand中的每个指令。
R2:找到同时执行RacePaircand的输入程序的线程交错。
之所以要满足这两个设计要求是因为单独的R1不能确保可以同时执行RacePaircand以触发数据竞争,因此分析应该识别同时执行RacePaircand的特定线程交错情况。
需求研究–传统的模糊测试 传统的模糊测试专注于对R1的解决,试图找到扩展内核代码覆盖范围的输入。由于根本不考虑R2,因此发现数据竞争基本都是无效的。
需求研究–线程交叉工具 关于随机线程交错工具(例如SKI [4]或PCT算法[5]),他们的重点是满足R2,试图探索特定(和静态)输入程序的所有可能的线程交错情况。由于他们不考虑R1,因此他们只能运行现有程序(例如基准测试),因此无法有效地探索大量代码空间,导致大部分内核未经测试。此外,因为线程交错工具基于随机调度,所以它们单独对R2的效率(即简单地搜索所有线程交错情况)也受到严重限制。
III. 设计&实现
RAZZER背后的关键理念是采用动静混合测试方案来对内核中潜在数据竞争点的分析。首先,RAZZER执行静态分析以获得十分近似的潜在数据竞争点。之后,RAZZER进行两阶段动态分析。第一阶段是单线程模糊测试,其重点是识别执行潜在竞争点(尝试满足R1)的单线程输入程序。第二阶段是多线程模糊测试。第二阶段在第一阶段的帮助下构建多线程程序,利用自定义管理程序确定性地控制线程交错(尝试满足R2)。找到竞争之后,RAZZER就会输出一个具体的用户程序(即触发数据竞争的程序)。Razzer还会检测内核是否出现了错误,如果RacePairtrue在程序后续执行过程中,导致了内核错误,则得到了一个RacePairharm。
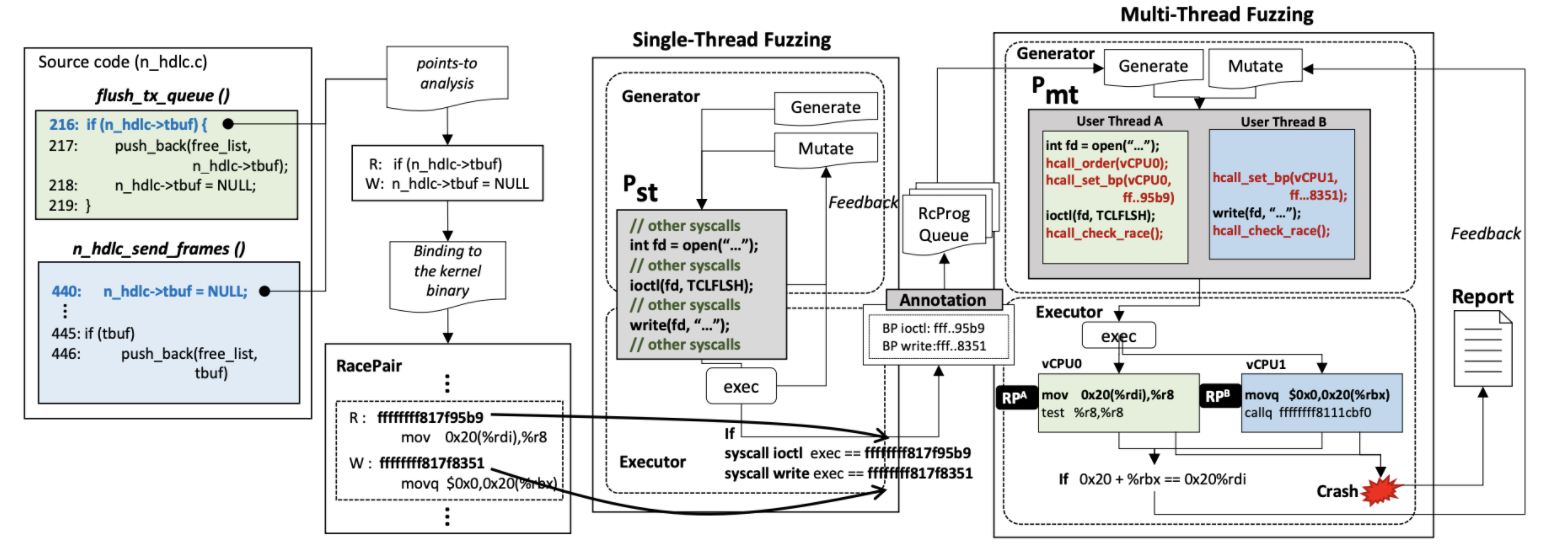
图2:RAZZER的整体架构
A. 静态分析识别潜在竞争点
静态分析的目标是识别内核中的所有RacePaircand,其中每个RacePaircand由两个内存访问指令组成,并且可能需要在运行时竞争。RAZZER在此处使用的是点对分析,但是一般而言点对分析在准确性和性能方面受到限制,并且会具有很高的误报率,因此RAZZER在此采用特有的方式对这个问题来进行解决。
首先是为了解决准确性问题,RAZZER允许点分析十分逼近RacePaircand集(即,某些RacePaircand可能不是RacePairtrue),并通过其动态模糊测试解决误报问题。其次,为了缓解性能问题,RAZZER执行内核的定制分区分析。 它根据模块组件对内核对象进行分区,并对每个模块执行预分析。 并且在对每个模块执行预分析时,RAZZER也始终提供核心内核模块。
值得注意的一点是,此处的静态分析不考虑内核中的同步原语(例如,read_lock(),br_read_lock(),spin_lock_irqsave(),up())。利用这些信息可以降低误报率(因为它可以帮助确定不能竞争的内存对)。
B. Hypervisor中的每核心调度程序
由于内核线程交错的非确定性和随机性,竞争条件很少表现出来。因此,RAZZER在定制的虚拟化环境中运行目标内核,以便RAZZER避免来自外部事件的非确定性行为。具体来说就是 RAZZER修改虚拟机管理程序为guest内核提供了以下功能:
- 为每个CPU核心设置一个断点:RAZZER提供了一个新的超级调用接口hcall_set_bp(),以便guest内核可以根据需要设置每个核心的断点。这个超级调用接口会在虚拟机guest内核使用两个参数时如下来个参数时被调用。
(1) vCPU_ID指定RAZZER应在其上安装断点的虚拟CPU(vCPU);
(2) guest_addr指定客户操作系统的地址空间中要安装断点的地址。
收到此超级调用后,虚拟机管理程序会在guest_addr上安装硬件断点,该断点仅对指定的vCPU有效。 - 在guest内核遇到断点后恢复执行内核线程:在两个客户内核线程停在它们各自的断点地址(即RacePaircand)之后,RAZZER恢复两个vCPU的执行,使得两个线程同时执行RacePaircand。 RAZZER在这里做出的一个重要决定是:应该首先恢复哪个内核线程?这对于识别数据竞争非常重要,因为某些竞争bug仅在特定执行任务上展示。恢复的工作流程如图3所示。
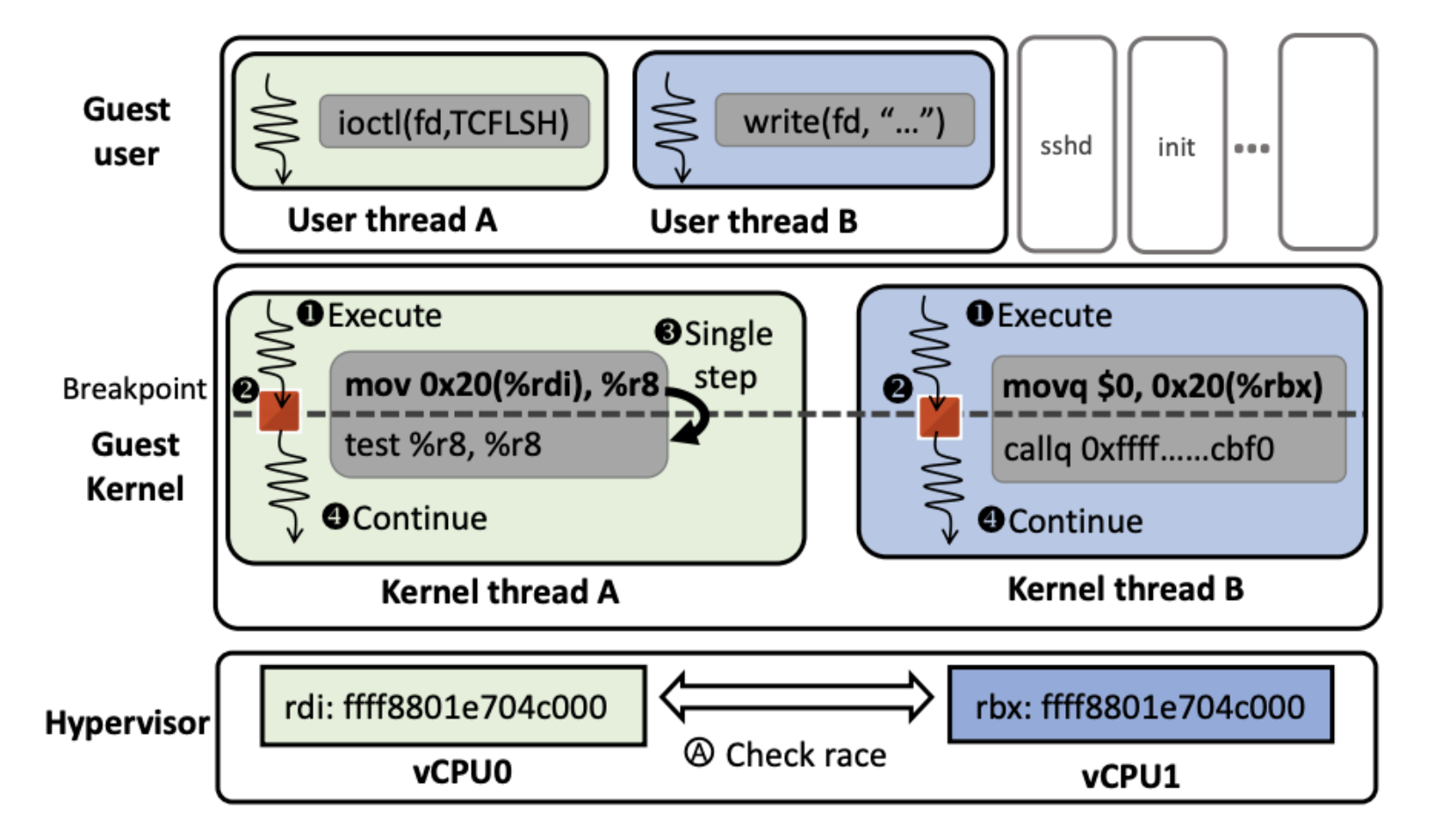
图3:RAZZER管理程序的工作流程
- 检查guest内核是否确实发生了竞争:当两个断点同时被触发时,我们的管理程序检查给定的RacePaircand是否实际导致竞争。 更具体地说,当RacePaircand中的两个存储器指令都命中断点时,我们的管理程序会对这些指令要访问的目标地址进行分析。 如果这些地址相同,那么RAZZER会得出结论,给定的RacePaircand真正参加竞争,将这样的一对推广到RacePairtrue。 从技术上讲,我们的虚拟机管理程序通过反汇编每个RacePaircand位置的指令并获得存储在每个vCPU中的具体寄存器值来计算目标地址值。
C. 通过两个阶段的Fuzz来发现竞争漏洞
RAZZER的模糊测试分两个阶段进行:
(i)单线程模糊测试阶段找到一个触发任何RacePaircand的单线程用户程序;
(ii)多线程模糊测试阶段最终找到一个多线程用户程序,该程序根据单线程阶段的结果触发一次攻击竞争。
要注意每个模糊测试阶段由两个组件组成,即生成器和执行器,其中生成器创建用户程序,然后执行程序运行程序。
1)单线程模糊测试:在这个阶段,单线程生成器最初生成Pst,一个带有一系列随机系统调用的单线程程序。 接下来,单线程执行程序运行每个Pst,同时测试Pst的每次执行是否会覆盖RacePaircand。如果覆盖,则单线程执行程序将Pst(带有被覆盖RacePaircand的信息注释)传递给下一阶段来进行多线程模糊测试。
单线程生成器 单线程生成器构造一个单线程用户程序(我们称之为Pst),执行一系列随机系统调用来测试内核的行为。 RAZZER使用以下两种策略构建Pst:生成和变异。 使用生成策略时,RAZZER会根据预定义的系统调用语法随机生成Pst。 此系统调用语法包括所有可用的系统调用以及每个系统调用的一系列合理参数值。 遵循此语法,RAZZER尝试通过随机选择一系列系统调用来构建合理的用户程序。 然后它随机填充每个系统调用的参数,并将其返回值随机地捎带到跟随系统调用的参数上。与生成相反,突变随机改变现有的Pst。 它可能会随机丢弃Pst中的一些系统调用,插入新的系统调用或更改某些参数值。
单线程执行程序 给定来自生成器的Pst,单线程执行器在执行以下两个任务时运行每个Pst。 首先,如果Pst的执行覆盖任何RacePaircand中的两个存储器访问指令,则RAZZER将这样匹配的RacePaircand信息注释到Pst。 然后RAZZER将这个带注释的Pst传递给多线程生成器,以便可以进一步检查它是否正在竞争。
2)多线程模糊测试:在单线程模糊测试阶段后,RAZZER进入多线程模糊测试阶段。 对于每个RacePaircand,多线程生成器将Pst转换为Pmt,Pst的多线程版本。 Pmt还配备了管理程序调用,以在给定的RacePaircand上确定性地触发竞争。 最后,多线程执行程序运行每个Pmt。 如果Pmt被确认为由管理程序触发竞争,则RAZZER将相应的RacePaircand提升为RacePairtrue,并通过将其反馈给生成器来继续改变Pmt。 此外,如果Pmt能够触发内核崩溃,RAZZER则会生成一份有关已识别的有害竞争的详细报告。
多线程生成器 多线程生成器使用带注释的Pst(包括RacePaircand)作为输入。 然后输出Pmt,也就是Pst的多线程版本,同时输入带注释的RacePaircand信息利用超级调用确定性地触发竞争。由Pst转换为Pmt的程序如图4所示

图5:RAZZER的多线程生成器算法
当Pmt中的RacePaircand指令都触发断点时,Razzer会检查访存指令的访问地址是否相同,如果相同,则判定为RacePairtrue。可以注意到在Pmt的最后加入了一些随机的syscall,这是为了当数据竞争造成了具有攻击效果的后果时,让程序报错。每当检测到一个RacePairtrue,就会把结果反馈回生成算法,并保持前面的代码不变,只修改后续随机添加的syscall,进行新的Fuzz。如果其中某个Pmt使kernel报错,则认为是发现了一个RacePairharm。
多线程执行程序 多线程执行程序的主要作用是运行Pmt以测试RacePaircand是否真正触发了竞争。 在运行时,它会在调用相应的racy系统调用之前,利用超级调用在RacePaircand指令中设置每核断点。 然后,hcall_check_race()通过同时检查以下两个条件来确定是否真正触发了竞争:
(1)如果管理程序确实捕获了两个断点;
(2)RacePaircand指令访问的具体内存地址是相同的。
要注意引起真正的竞争本身并不一定意味着有害的竞争,RAZZER会在竞争后触发系统调用,以便从各种竞争中辨别出有害的竞争。 大多数现代内核使用运行时竞争检测机制来检查是否发生了有害竞争。 例如,Linux内核使用各种动态技术来检测有害的竞争。 示例是lockdep[6],KASAN [7]或由内核开发人员手动插入的断言。 我们在构建内核二进制文件时启用了所有这些技术,以便RAZZER可以利用这种增强的竞争检测功能。
RAZZER的一个重要特征是它向Pmt上的多线程生成器提供反馈,导致真正的竞争(即使是良性竞争),这样Pmt可以进一步变异,但仅限于与竞争后行为相关的部分。
D. 实现
- RAZZER的静态分析基于LLVM 4.0.0和SVF[8]。
- RAZZER的虚拟机管理程序在QEMU 2.5.0上实现,并利用KVM(基于内核的虚拟机)来利用硬件加速。
- RAZZER的模糊器是基于Syzkaller[9]实现的。
IV. 评估
在评估之前首先要准备好目标内核,RAZZER不需要手动修改要分析的目标内核,它只需要先使用LLVM和GCC对目标进行build,之后运行在RAZZER的hypervisor虚拟机上即可。
- 图5总结了RAZZER确定的竞争漏洞。
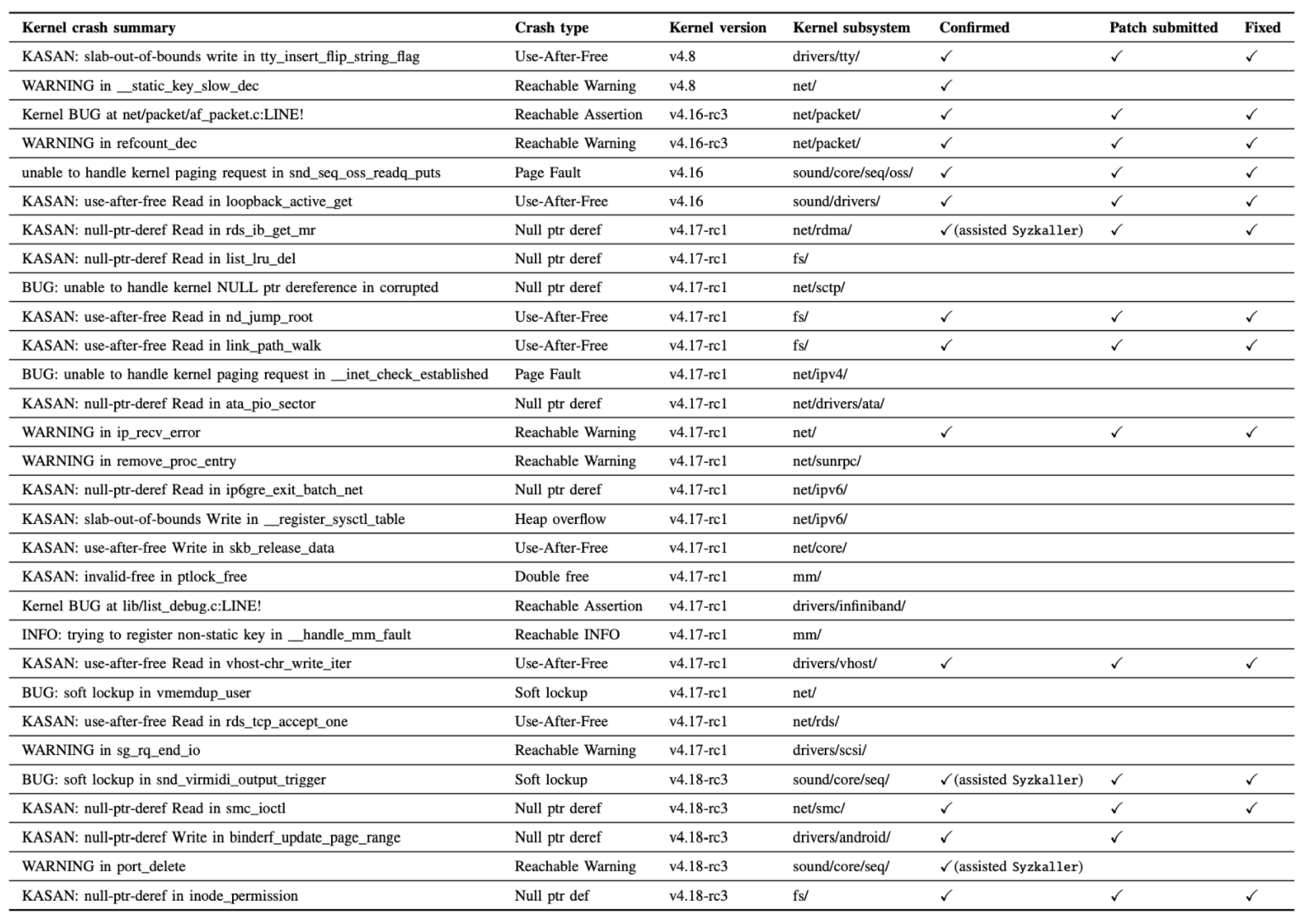
图5:RAZZER新发现可以造成安全缺陷的竞争漏洞清单
- 图6展示了RAZZER发现新的有害竞争的效率。在这个图中,主要描绘了两类bug:(i)通过单线程模糊测试发现的非竞争bug; (ii)通过多线程模糊测试发现的竞争bug。
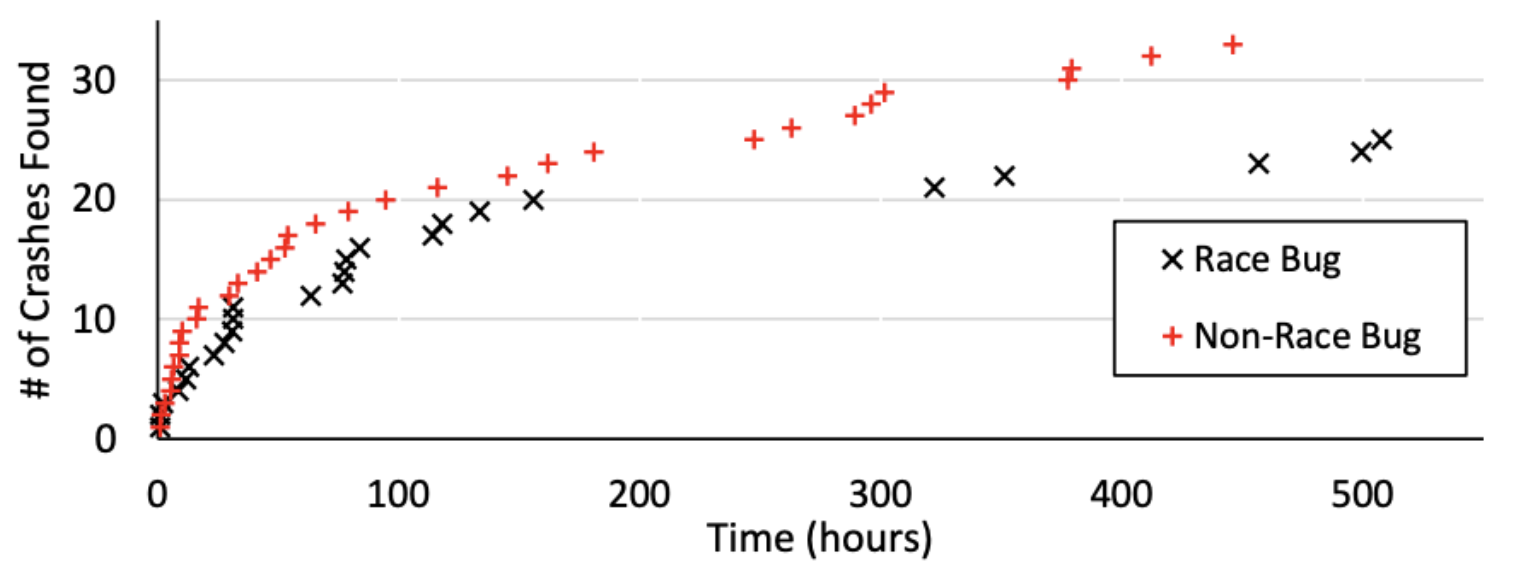
图7:随时间变化的唯一崩溃次数
- 为了证明RAZZER分区分析的有效性,作者测量了从整个内核获取所有RacePairscand所需的时间,如图8所示。
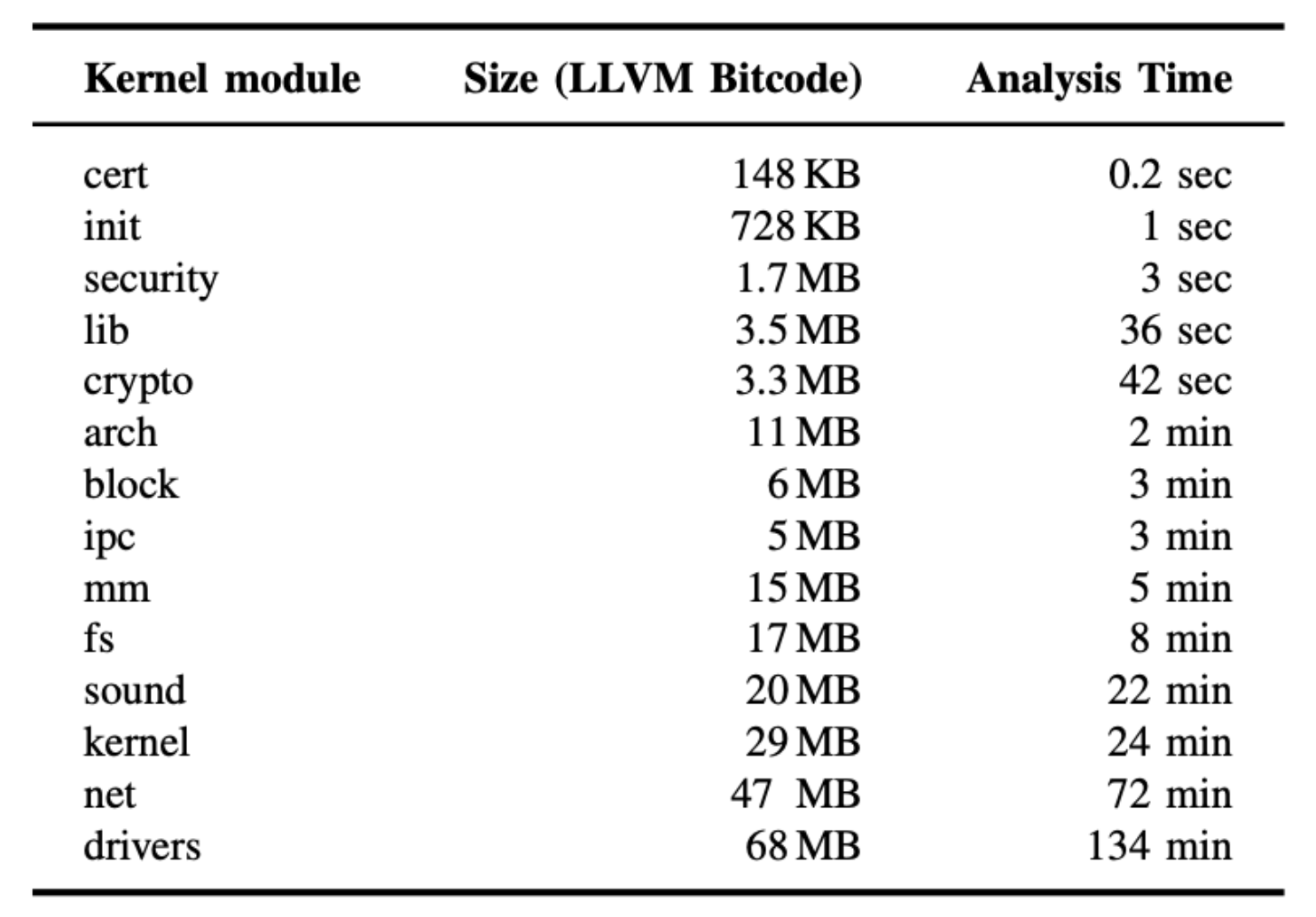
图8:RAZZER静态分析的性能
- 鉴于RAZZER利用超级调用来启用vCPU的确定性行为,因此需要额外的开销来与管理程序进行通信。为了了解由于管理程序引起的开销,测量了每次超级调用的经过时间100M次并计算了平均值。图9显示了RAZZER的超级调用的性能开销。

图9:执行RAZZER的超级调用时的性能开销
- 模糊测试的执行吞吐量可能是模糊技术效率的间接测量,但更直接和重要的测量应该是找到bug所需的时间(即本文中的有害竞争)。 为了证明这一点,我们测量了发现以前已知的有害竞争CVE-2017-2636,CVE-2016-8655和CVE2017-17712所需的执行次数,同时运行了10个小时。如图10所示,RAZZER发现所有这些以前已知的竞争具有合理的执行次数(即从246 K到1,170 K)以及在合理的时间内(即从7分钟到26分钟)。 然而,Syzkaller未能找到所有这些案例,尽管在10小时内从5 M到37 M生成/突变程序执行。 特别是基于这些CVE案例,表明RAZZER比Syzkaller更快,至少为23至85倍。
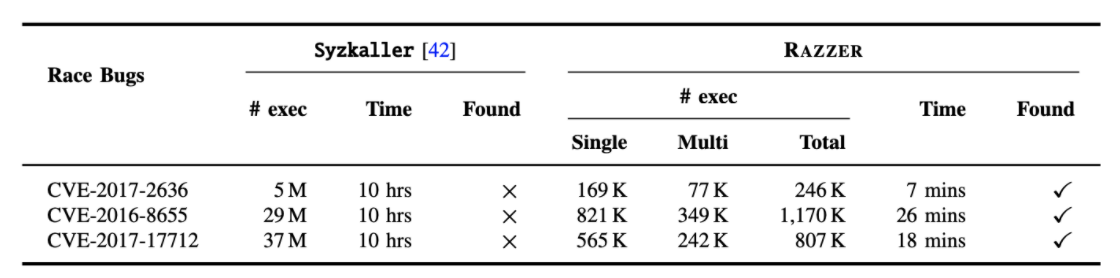
图10:Syzkaller和RAZZER在查找触发竞争的用户程序时的效率。 作者测量了执行总次数和找到之前已知竞争所需的时间。 RAZZER在合理的时间内找到了所有已知的竞争,而Syzkaller在10小时的给定时间内没有发现任何竞争(v4.8)。
- 图11显示了在运行RAZZER和SKIEmu时触发每个竞争所需的执行次数。 由于RAZZER仅探索与RacePairscand相关的线程交错(通过运行给定的用户程序发现),因此探索的线程交错情况要少得多,RAZZER所需的执行次数远少于SKIEmu,范围从30次减少到398次。 这个结果还表明,SKIEmu探索的许多线程交错案例与竞争无关,这标志着RAZZER在满足R2方面的有效性。
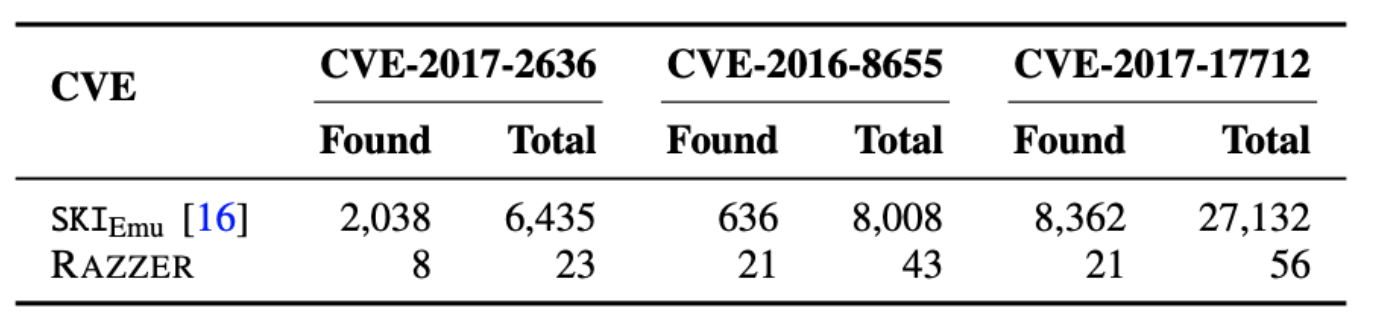
图11:SKIEmu和RAZZER在揭示触发竞争的线程交错方面的效率。 Found列显示了查找交错所需的执行次数(通过重复实验5次并计算平均值获得),Total列显示每个工具所需的理论最大执行次数(v4.8)。
V. 相关工作
面向内核的Fuzzing测试的主要思想是通过给内核驱动输入大量畸形数据,观察操作系统对这些畸形数据处理后的反应,如果出现了蓝屏或者崩溃等信息,则再对dump信息进行静态分析定位漏洞[10]。这类工具如IOCTL、Syzkaller等。此节将主要介绍那些能够识别(或协助识别)数据竞争的技术。
动态模糊测试 最近的许多研究表明,模糊测试是一种很有前途的技术,用于发现用户程序中[11]和内核[12]的bug。 模糊测试的关键优势不仅在于该方法可以有效地发现目标程序中的bug,而且还可以避免误报,因为它会产生再现bug的输入。 然而,据我们所知,所有模糊测试技术在用于识别竞争bug时效率低下,主要是因为他们的设计不适合竞争。 虽然大多数模糊器专注于利用先前探索的执行覆盖,但他们不考虑线程交错。 与这些相比,本文介绍的RAZZER则综合考虑了执行覆盖和线程交错从而更有效地发现数据竞争。
动态线程调度程序 一些研究例如试图通过实现随机化每线程执行调度的定制线程调度器来找到引起竞争的线程交错的实例。 特别是,PCT算法[13]和SKI [4]通过探索所有可能的线程交错情况来发现用户程序或内核中的竞争。 这两种方法的局限性是:(i)他们不生成(或改变)输入程序,因此它找不到触发数据竞争的新程序; (ii)它们无法找到同时执行RacePaircand的输入程序的线程交错,因为它们必须搜索所有可能的线程交错情况的非常大的空间。 事实上,RAZZER的设计灵感来自PCT算法和SKI它通过定制模糊过程来满足R1,同时通过对RacePairscand进行优先搜索来有效地满足R2。
动态竞争检测器 许多研究[14]试图通过收集关于竞争的丰富的上下文信息来改善运行时的竞争检测能力。 这些基本上与RAZZER正交,也就是说它们与RAZZER一起部署后,RAZZER的竞争检测能力也可以得到增强。
特别是,ThreadSanitizer [15]是由谷歌开发的企业级竞争检测器,最近也应用在了Linux内核发布之前的检测。 为了在检测竞争时增强性能,TxRace [16]利用硬件事务存储器,ProRace [17]利用性能监控单元。 存储器采样技术有选择地监视存储器访问以优化性能。 RaceMob [18]从静态分析生成的潜在数据竞争中众包运行时竞争测试。 Snorlax [19]建议使用粗略交错假设来利用粗粒度定时信息来确定事件的线程交错。
静态分析 静态分析已被广泛用于发现未知的bug。在此类别中,我们将重点讨论与竞争bug检测或点对分析实施相关的静态分析工作。 Relay [20]是一个静态的竞争检测器,适用于内核等大型程序。 Relay通过执行基于锁定的自下而上分析生成RacePairscand,同时总结每个函数的行为。 RacerX [21]也可用于查找大型复杂多线程系统的竞争条件和死锁。由于单独使用静态分析技术的局限性,这些基本上导致高的误报率(例如,Relay在Linux内核上显示出84%的误报率),严重限制了它们在实践中的使用。然而,RAZZER还利用动态分析技术,解决了高误报率的可能性。在点对分析实施方面,最近提出了K-miner [22],通过程序间和上下文敏感性分析揭示商品操作系统中的内存损坏漏洞。 RAZZER的静态分析是基于K-miner的实现而构建的,但经过修改以通过点分析来识别RacePairscand。
VI.讨论
静态分析中的漏报 由于RAZZER依赖于静态分析的结果,如果RacePaircand中缺少任何真正的竞争对,则会导致RAZZER对bug的漏报。 静态分析的这种丢失情况可能主要是因为分区分析发生的。 因为RAZZER的分区分析基于跨越不同内核模块的竞争很少发生(例如,文件系统和终端设备驱动程序)这个假设。 因此,如果假设的情况发生了,RAZZER的RacePaircand将不会包含这样的竞争对,从而导致漏报。要解决这个问题,可以去除RAZZER的分区分析,采用更精确的静态分析技术。
将RAZZER应用于其他系统 RAZZER是一种灰盒模糊测试,所以只要源代码和对应的虚拟环境的支持,将RAZZER应用于其他现代操作系统(如Windows,MacOSX,FreeBSD,以及一些开源内核)是很容易的。 从介绍以及开源的代码上来看RAZZER只是在处理系统调用调用模型的时候是针对Linux的,其余所有设计都是平台无关的,因为其核心机制可以离线(即静态分析)或透明(即定制执行系统管理程序)。
变异策略 如果将RAZZER测试内核竞争漏洞的思想应用于用户程序,可能不需要在识别竞争后再使用其他变异策略。 因为与偶尔允许使用竞争提高性能的Linux内核不同,大多数用户程序中都会存在数据竞争这样的bug。
VII.结论
本文基于RAZZER这种结合静态分析和动态模糊测试的方案,来对内核竞争漏洞的模糊测试技术做了介绍。RAZZER是一款为竞争漏洞量身定制的模糊测试工具,不仅其实现方案极具代表性,其实的实际效果也非常的好。 它利用静态分析来发现潜在的数据竞争点,以指导模糊器识别竞争。 此外,它修改底层管理程序以确定性地触发竞争。 对RAZZER的评估证明了其强大的检测竞争的能力。 它已经在Linux内核中发现了30个新的竞争,并且与其他最先进的工具(特别是Syzkaller和SKI)进行了比较研究,证明了它在检测内核中的竞争漏洞方面的出色表现。
REFERENCES
[1] MITRE. CVE-2016-8655., 2016. https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2016-8655.
[2] MITRE. CVE-2017-2636., 2017. https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2017-2636.
[3] MITRE. CVE-2017-17712., 2017. https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2017-17712.
[4] Fonseca P , Rodrigues R , Björn B. Brandenburg. SKI: exposing kernel concurrency bugs through systematic schedule exploration[C]// Usenix Conference on Operating Systems Design & Implementation. USENIX Association, 2014.
[5] Burckhardt S , Kothari P , Musuvathi M , et al. A randomized scheduler with probabilistic guarantees of finding bugs[J]. ACM SIGARCH Computer Architecture News, 2010, 38(1):167.
[6] I. Molnar. Runtime locking correctness validator, 2018. https://www.kernel.org/doc/Documentation/locking/lockdep-design.txt.
[7] Kernel address sanitizer, 2018. https://github.com/google/kasan/wiki.
[8] Sui Y , Xue J . [ACM Press the 25th International Conference - Barcelona, Spain (2016.03.17-2016.03.18)] Proceedings of the 25th International Conference on Compiler Construction - CC 2016 - SVF: interprocedural static value-flow analysis in LLVM[J]. 2016:265-266.
[9] D. Vyukov. Syzkaller, 2015. https://github.com/google/syzkaller.
[10] 史记, 曾昭龙, 杨从保, et al. Fuzzing 测试技术综述[J]. 信息网络安全, 2014(3):87-91.
[11] Pham V T , Roychoudhury A . Coverage-based Greybox Fuzzing as Markov Chain[C]// Acm Sigsac Conference on Computer & Communications Security. ACM, 2016.
[12] You W , Zong P , Chen K , et al. SemFuzz: Semantics-based Automatic Generation of Proof-of-Concept Exploits[C]// Acm Sigsac Conference. ACM, 2017.
[13] Burckhardt S , Kothari P , Musuvathi M , et al. A randomized scheduler with probabilistic guarantees of finding bugs[J]. ACM SIGARCH Computer Architecture News, 2010, 38(1):167.
[14] Veeraraghavan K , Chen P M , Flinn J , et al. Detecting and Surviving Data Races using Complementary Schedules[C]// Proceedings of the 23rd ACM Symposium on Operating Systems Principles 2011, SOSP 2011, Cascais, Portugal, October 23-26, 2011. ACM, 2011.
[15] Serebryany K , Iskhodzhanov T . ThreadSanitizer: data race detection in practice[C]// Workshop on Binary Instrumentation & Applications. ACM, 2009.
[16] Zhang T , Lee D , Jung C . TxRace: Efficient Data Race Detection Using Commodity Hardware Transactional Memory[J]. Acm Sigplan Notices, 2016, 50(2):159-173.
[17] Zhang T , Jung C , Lee D . ProRace: Practical Data Race Detection for Production Use[J]. Acm Sigarch Computer Architecture News, 2017, 45(1):149-162.
[18] Kasikci B , Zamfir C , Candea G . RaceMob: Crowdsourced data race detection[C]// Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles. ACM, 2013.
[19] Kasikci B , Cui W , Ge X , et al. [ACM Press the 26th Symposium - Shanghai, China (2017.10.28-2017.10.28)] Proceedings of the 26th Symposium on Operating Systems Principles, - SOSP \”17 - Lazy Diagnosis of In-Production Concurrency Bugs[J]. 2017:582-598.
[20] Voung J W , Jhala R , Lerner S . RELAY: static race detection on millions of lines of code[C]// Proceedings of the 6th joint meeting of the European Software Engineering Conference and the ACM SIGSOFT International Symposium on Foundations of Software Engineering, 2007, Dubrovnik, Croatia, September 3-7, 2007. ACM, 2007.
[21] Engler D . RacerX : Effective, static detection of race conditions and deadlocks[C]// Proc. ACM Symposium Operating Systems Principles, 2003. ACM, 2003.
[22] D. Gens, S. Schmitt, L. Davi, and A.-R. Sadeghi. K-miner: Uncovering memory corruption in linux. In Proceedings of the 2018 Annual Network and Distributed System Security Symposium (NDSS), San Diego, CA, Feb. 2018.